Abstract
Inside IBM i5/OS™ is the little known but important journal recovery count function. While this function ships from IBM with a default value, many shops have found it useful to adjust this value. If you set the value too low, you can experience added performance overhead at run time. If you set it too high, you can experience long duration initial program load (IPL) recovery steps. Instead, you must simply select an effective value that works for your shop and your environment.
Written by Larry Youngren, Software Engineer
IBM Systems &Technology Group, Development
Development iSeries Journaling
Chris Kundinger
System i High Availability -
SLIC Journal and Commitment Control
Contents
A little background
Because no one wants IPL, especially an abnormal IPL, to take long, throttling mechanisms are built into i5/OS. One of those mechanisms is the journal recovery ratio, which in turn is adjusted by modifying the journal recovery count. This ratio is intended to limit the number of journal entries that must be visited and replayed if the machine goes down abruptly without saving the contents of the main memory.
The original default setting of this internal threshold was 50,000 (50k) entries. This setting indicated that i5/OS must attempt to limit the quantity of journal entries to be replayed per journal to no more than the most recent 50k. The System i™ platform shipped with the default value of 50k for many releases prior to i5/OS.
Most of the time consumed during the subsequent journal IPL recovery or replay step influenced by this setting was spent waiting for page faults, to ensure that each affected row of a database table is resident in main memory just before the journal attempts to replay the matching database operation. The 50k value for the recovery count was selected years ago when underlying disk technology was much slower than most shops have installed today. The reason for choosing 50k was to attempt to keep the total quantity of recovery time dedicated to replaying recent in-flight database operations to approximately 15 minutes or less thereby reducing total IPL duration.
Is 50k still the optimal value?
Over the years, both the operating system’s software recovery algorithms and the underlying disk RPM rates have improved such that most machines can easily replay the most recent 50k journal entries within far less than 15 minutes (in fact mere seconds, not minutes on some high end machines). Considering this improvement, a universal default 50k recovery count objective now seems small. For that reason, a number of shops, especially those that have aggressive journal traffic, have elected to increase their journal recovery count (journal recovery ratio). Some shops have increased this value by two times, some by five times, and a few even more aggressively.
Why have shops changed the journal recovery count? The reason is because any such ratio represents a trade-off, either a pay-me-now or pay-me-later kind of trade-off. The lower the ratio is, the more aggressively the underlying run-time background SLIC tasks have to work to ensure that the aggressive IPL duration objective is satisfied. That is, no more than 50k actions are to be replayed at IPL time, which is achieved by furiously sweeping recent database row images from memory to disk at run time more frequently so that there is no longer any need to consider replaying these actions at IPL time. As a consequence, those database row images, which have confidently been written to disk, do not need to be replayed if the machine crashes. This is good, but it comes at a price.
By contrast, the higher the setting of your journal recovery ratio is, the more these background sweeper tasks can back off, not schedule so many disk writes of dirty database pages at run time, and allow the resulting abnormal IPL to take a bit longer. It is clearly a trade-off. You cannot have both zero run-time housekeeping overhead and zero IPL recovery time duration. Therefore, selecting a practical and reasonable middle ground makes sense.
The value that you select for this journal recovery ratio directly influences the run-time overhead versus IPL-time duration trade-off.
Why is it called a ratio?
The more objects, such as physical files, that are associated with this journal and are currently open and actively changed at the same time, which puts them at risk of needing IPL time replay or recovery processing from the journal in the event of a crash, the higher you want to set this ratio to ensure acceptable run-time performance. In fact, that is one of the reasons it is called a "ratio". The actual calculation within the operating system takes the value that you prescribe, such as 50k, and divides this number by the quantity of journaled objects that are currently flagged as exposed.
For example, you have only one physical file open and it is the source of all journal entries that are currently being deposited. i5/OS divides 50k by one object and gets a result of 50k. Therefore, when the background SLIC housekeeping task has moved all recently changed row images to disk, it waits until another 50k journal entries arrive.
If you have 100 journaled files open that are actively being changed, i5/OS divides the 50k value that you prescribed by 100 and realizes that it has to wait for every 50k/100 or 500 new journal entries, thereby producing a much shorter wait. Therefore, the ratio 50k/x, where x is the number of journaled objects at risk, triggers the frequency of the wake-up call.
The faster that new journal entries arrive, and the more distinct journaled objects (in such an exposed state) that take the shorter the duration of waits, the more frequently and aggressively the background SLIC housekeeping tasks have to work. For this reason, to give these tasks a break, some shops elect to increase their journal recovery count and thereby reap some run-time performance relief.
What value should you use?
You might want a ratio that is larger than the default of 50k (up through V5R3). Values of 100,000 or even 150,000 may make sense for many shops. If you have an especially aggressive journal deposit rate (more than 500,000 new journal entries per minute) or a lot of actively changing or exposed journaled objects (more than 200 open and being changed at the same time), you may want to select an even larger setting such as 250,000. In fact, the new shipped default for this value starting in V5R4 is 250,000.
While these are rough rules-of-thumb, you might want to examine other pieces of evidence on your machine to see if your background housekeeping tasks are able to handle the workload. To perform a more in-depth analysis, you can use these steps:
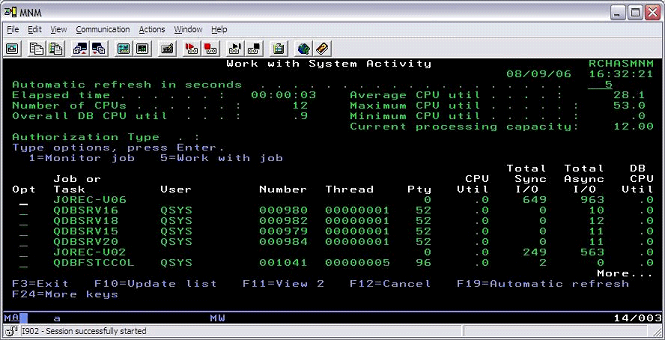
- Enter the Work with System Activity (WRKSYSACT) command (part of the OS/400 Performance Tools package 5722-PT1, which many shops have installed).
- Press F16 to sort the resulting activity.
- Specify option 2 (sort by I/O) so that the most aggressive disk read/write jobs move to the top.
- Press F15 so that only SLIC tasks are visible.
In the following Work with System Activity screen, you see two JOREC_U jobs. By refreshing this screen during your most performance-critical part of the day, you can see how busy your background SLIC journal recovery ratio housekeeping tasks tend to be. Observe not only how much CPU they are consuming, but more importantly how much disk I/O they are generating. These tasks are named JOREC_Uxxx, where xxx are numbers. Tasks named JOREC_Uxxx are servicing ordinary journals. The tasks that have a first letter after the underscore of “D” are servicing default system-provided journals, such as the system managed access path protection (SMAPP) journals.
In summary, the naming convention is:
- D = Default, system-provided journal
- U = User-provided journal
 How does this become easier to manage in V5R4?
Prior to V5R4, you could only influence wait time on a system-wide basis; there was only one system-wide journal recovery ratio setting. V5R4 allows you to customize the wait time on a per journal basis. With the new V5R4 support, you can influence the tasks with a “U” in their name.
In addition, beginning in V5R4, a new warning message (CPI7020) surfaces when the system notices that these recovery ratio housekeeping tasks appear to be having a difficult time meeting your specified objective. The message is sent to message queue QSYSOPR and redundantly to any message queue that you may have designated on the CRTJRN or CHGJRN command. If this new message surfaces, pay attention to it. It is usually an indication that either:
How does this become easier to manage in V5R4?
Prior to V5R4, you could only influence wait time on a system-wide basis; there was only one system-wide journal recovery ratio setting. V5R4 allows you to customize the wait time on a per journal basis. With the new V5R4 support, you can influence the tasks with a “U” in their name.
In addition, beginning in V5R4, a new warning message (CPI7020) surfaces when the system notices that these recovery ratio housekeeping tasks appear to be having a difficult time meeting your specified objective. The message is sent to message queue QSYSOPR and redundantly to any message queue that you may have designated on the CRTJRN or CHGJRN command. If this new message surfaces, pay attention to it. It is usually an indication that either:
- Too many active objects are all connected to the same journal for the housekeeping tasks to service all of them in a timely manner. That is, the denominator in your ratio calculation is too high.
- The journal recovery objective is so low (aggressive) compared to the rate of arrival of new journal entries that it is impractical for the background housekeeping tasks to keep up and achieve your IPL recovery duration objective; you need to allow longer waits. That is, your numerator for your ratio calculation is too low.
If you see this message, we recommend that you increase your journal recovery ratio.
How do you change the ratio?
Prior to V5R4, you could change the ratio by using a little publicized API and could do so only on a system-wide basis, so all journals had the same ratio. Beginning in V5R4, you can customize the ratio per journal by using the CHGJRN command. The CHGJRN command provides the JrnRcyCnt (Journal Recovery Count) keyword to let you customize your recovery ratio:
CHGJRN . . . JNRCYCNT(250000)
The value that you supply for JrnRcyCnt can be as small as 10,000 (that is five times more aggressive than the default setting prior to V5R4 for shorter waits and busier sweeper tasks) all the way to 2,000,000,000 (for longer naps).
If 250k is good, is 2 billion even better?
Just because you can set the recovery ratio extra high, should you? The answer is probably not.
While it is true that a larger setting for your journal recovery count can help reduce the frequency of performing housekeeping work (writing the modified rows of journaled database files to disk) and less frequent disk writes can help relieve performance overhead at run time, there is a point of diminishing returns. In fact, there can even be negative run-time consequences if you get too eager and set the ratio extremely high. The higher you set this ratio, the more likely it is that database page images will linger longer in main memory. Consequently, if you set this value too high, the resulting working set of your main memory may become larger, and therefore older journal entries tend to be retired (that is flagged as not essential for proper IPL recovery) less aggressively. Using extremely high journal recovery count values (for example 10,000,000 or more) tends to increase the likelihood that the journal receivers you want to discard to free space insist on remaining longer.
Nobody likes bloat
Consider a case where you have SMAPP enabled (a hidden style of journaling) and then select an extremely large journal recovery count. In this case, the space normally set aside within your journal receivers for such access path IPL replay images can become overburdened and overflow into the normal journal area. This in turn results in “journal bloat” and makes the size of your journal receivers increase rapidly, which is another sign that you have set the journal recovery ratio too high. While such overflow in no way impedes proper IPL recovery, it comes at a price of poorer performance at run time. This especially happens in a remote journal environment since these overflowed, normally hidden, SMAPP-induced journal entries tend to clog the communication pipe.
A revised setting of about 250k for your journal recovery ratio is not a bad choice for most shops. A setting of 2 million is probably too high. Remember that we are trying to find the right setting. For most shops, the 50k default (for releases through V5R3) is probably too low, while 2 million is probably too high, but somewhere in the 150k to 250k range is probably just right.
Are you taking a risk of database data loss by using a larger value?
Upon hearing of the opportunity to adjust wait times and thereby allow database row images to linger longer in main memory, you might jump to the conclusion that you are encouraging a greater likelihood of loss of recent updates. Such a fear is unfounded.
Taking longer waits does not alter the frequency with which the journal entries themselves travel to disk; it is the journal entries that ensure that all database changes are replayed if your system crashes.
The increased wait times only influence how aggressively the system works to ensure that the bookkeeping associated with the database rows protected by these journal entries also leaves main memory. For applications that keep files open for long periods of time and tend to update the same rows time after time, keeping the row resident is a good thing. It is also a good thing to allow the bookkeeping data to reach disk periodically. Getting too aggressive regarding the flushing of this metadata places a high burden on your disks at run time. You cannot have both extremely short IPLs and no run-time overhead. Therefore, allowing longer waits (that is selecting a larger journal recovery ratio) may strike the proper balance between run-time overhead and abnormal IPL duration without increasing the true risk of data loss because the journal itself covers you.
What if you are not on V5R4 yet?
While V5R4 is clearly the release that makes management and customization of this recovery setting easier by using the CHGJRN command, there are ways to get a similar effect in both V5R2 and V5R3.
For V5R2, although you cannot customize the recovery count on a per journal basis, you can use the following API to revise the default setting system wide. You replace the 50k default value with a new value of your choice. The following example shows the syntax for V5R2:
API: Call QJOCHRVC 100000 { V5R2 }
Increases recovery ratio 2-fold from 50k to 100k (thereby reducing the background housekeeping load by 50%)
For V5R3, the same API uses a syntax that matches more closely what other APIs provide, namely a consistent error structure. The following example shows the syntax for V5R3 to accomplish the same thing:
CALL PGM(QJOCHRVC)
PARM( X'000186A0' { This is 100,000 expressed in Hex }
X'00000000000000000000000000') {This is the error structure as a Hex string}
As you can quickly recognize, the V5R4 approach is more intuitive than the earlier API approaches.
Conclusion
Whether your desire is to improve run-time performance, gain better control over abnormal IPL duration, or merely customize background SLIC sweeper task behavior per journal, the new Recovery Count parameter (JrnRcyCnt) on the CHGJRN command for V5R4, along with a watchful eye for the CPI7020 message or sampling of the WRKSYSACT screen, affords you the opportunity to find the right setting for your environment.
